The problem
The usual ASCII string comparison is simple -
- Normalize both strings by converting them to lower-case
- Compare the strings
# ascii string comparison
def compare_ascii(str1: str, str2:str) ->bool:
return str1.lower == str2.lower
On the other hand, unicode string comparison is much harder to do. The strings cannot always be normalized by simple uppercase/lowercase conversion. Eg - scripts that don't have the concept of uppercase/lowercase, but still have different representations for the same character.
Note : Unicode calls the written letters to be part of scripts. Not languages.
Eg - The language Hindi is written in Devanagari script
Here is comparison of 2 different representations of the letter 'a' in different scripts:
print('a')=='𝒂'
>> False
So, how do you even tackle this problem?
What makes unicode string comparison hard?
The source of the problem is -
- Multiple representations of the same character in different scripts
- Multiple representations of the same logical characters in the same scripts
Multiple representations of the same character in different scripts
Example:
Here are the ways in which the letter 'a' can be written:
a 𝒂 ᵃ 𝘢 𝖆 ª 𝓪 𝚊 𝑎 𝗮 ₐ ⓐ 𝕒 𝖺 𝒶 𝙖 𝐚 𝔞
And when you compare these characters, the comparison will fail.
# compare `𝖺` and `a`
print('𝖺'=='a')
>> False
# compare lowercase representations
>>> print('𝖺'.lower()=='a'.lower())
False
Multiple representations of the same logical characters within a script
Example - In the German script 'ß' and 'SS' are equivalent. But, they cannot be directly compared.
'ß' == 'SS'
>> False
'ß'.lower() == 'SS'.lower()
>> False
So, to compare such strings, you need a smarter comparison system. The system should know which characters are logically equivalent. The python unicodedata module helps with this.
Solution
The solution has 2 steps:
- Normalize the unicode strings
- Make the normalized strings caseless
- Compare the normalized & caseless strings
from unicodedata import normalize
def check_equality_unicode(str1: str, str2:str) -> bool:
str1_normalized = normalize("NFKC",str1)
str1_normalized_caseless = str1_normalized.casefold()
str2_normalized = normalize("NFKC",str2)
str2_normalized_caseless = str2_normalized.casefold()
return str1_normalized_caseless == str2_normalized_caseless
This function is universal - It works for both Unicode and ASCII strings.
"NFKC" used above is a normalization form. There are 4 standard unicode normalization forms, each with different behaviours. More on them later.
Test cases
There are 3 test cases that you can put into in your codebases:
check_equality_unicode('Σίσυφος', 'ΣΊΣΥΦΟΣ')should equate to Truecheck_equality_unicode('a', 'a')should equate to Truecheck_equality_unicode('abc', 'ABC')should equate to True
Normalization in depth
The 4 normalization forms
There are 4 normalization form available for unicode:
NFD- Normalization Form D - Characters undergo canonical decompositionNFC- Normalization Form C - Characters undergo canonical decomposition, followed by canonical compositionNFKD- Normalization Form KD - Characters undergo compatibility decompositionNFKC- Normalization Form KC - Characters undergo compatibility decomposition, followed by canonical composition
Legend to understand the naming scheme:
- NF = Normalization Form
- D = Decomposition
- C = Composition
- K = Compatibility
A table makes their differences clearer -
| Form | Normalization form | Canonical Decomposition | Compatibility Decomposition | Canonical Composition |
|---|---|---|---|---|
| NFD | Form D | Yes | ||
| NFC | Form C | Yes | Yes | |
| NFKD | Form KD | Yes | ||
| NFKC | Form KC | Yes | Yes |
The decomposition can be canonical or compatible. But the re-composition is always canonical.
More details are available in unicode's documentation - unicode.org - Unicode Normalization Forms
Choosing a normalization form
Choice of normalization form depends on the application. The decision is made by answering by two questions:
- Which decomposition does the application need - canonical or compatibility?
- After the characters are decomposed, should the characters to be re-composed canonically?
Canonical vs compatibility decomposition
The compatibility decomposition is built over canonical decomposition, by putting in additional rules. The compatibility conversion transforms characters into their more common forms. This "simplification" using more common forms leads to some information loss. This is the reason why all canonical sequences are compatible, but all compatible sequences are not canonical.
Following is an example from the original unicode.org document.
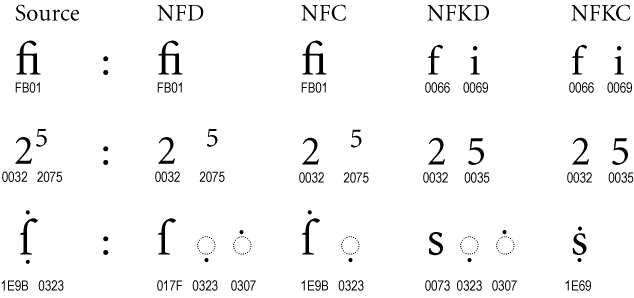
Notice how the exponent 5 gets converted into a simpler integer 5 by the Compatibility Decomposition algorithms of NFKD and NFKC. This simplification causes information loss - when looking at the normalized string, there is no way to know if the 5 originally was an exponent 5 or a normal 5.
Information loss in normalization
Normalization causes information loss. Once a string is normalized, it cannot always be converted back to the original string.
Here's an example - Suppose an ASCII string "HelLO TheRE" is converted to lowercase - "hello there". During this operation, the information that told which characters are uppercase got lost. So now, the lowercase "hello there" cannot be reverted back to the original "HelLO TheRE".
A similar thing happens during unicode normalization. Once a string is normalized, it cannot always be converted back to the original form due to information loss.
There are several reasons for this. Some of them are:
- Information loss caused during to the "simplification" performed by the compatibility form of character representation
- Information loss caused during to composition and decomposition
Here is an example from stackoverflow discussion on NFC vs NFD normalization - stackoverflow - When to use Unicode Normalization Forms NFC and NFD?
U+0387 GREEK ANO TELEIA (·) is defined as canonical equivalent to U+00B7 MIDDLE DOT (·) This was a mistake, as the characters are really distinct and should be rendered differently and treated differently in processing. But it’s too late to change that, since this part of Unicode has been carved into stone. Consequently, if you convert data to NFC or otherwise discard differences between canonically equivalent strings, you risk getting wrong characters.
When to and when not to use normalization
WHEN TO USE?
Normalization is required when two strings are being compared. Especially when dealing with non-english strings in multi-lingual apps.
- String comparison - eg - checking if a username is already taken
- De-duplication in datasets - strings are normalized strings before checking for duplicates in datasets. Typically used in llm training datasets, where the paragraphs are normalized and then their hash is then used to detect duplicates.
WHEN NOT TO USE?
By default, never normalize during data storage. If you're overriding this default, you should have a very good reason for it. If you're normalizing a string before storing it into a database, check if it is feasible to store both versions of the string - original(un-normalized) and normalized.
If you have good argument for normalization before storage, only then change this default, and store the strings normalized.
Don't use normalization during storage in use cases where the information loss due to normalization can cause problems. Normalization can change the way a string looks.
Some examples are:
- Normalization will cause problem in user typed strings. Eg - profile names, profile description, comments etc. The user might say "why is this text not looking like what I typed?".
- You may also break regulation in some strictly regulated industries, where storing data as-it-is is extremely important. Eg - legal document storage.
Resources
Further reading
- Tonsky.me - The Absolute Minimum Every Software Developer Must Know About Unicode in 2023
- Hn article
- W3C Standard Document: Character Model for the World Wide Web: String Matching
- Microsoft.com - Using Unicode Normalization to Represent Strings
Sources
- Stackoverflow - Normalizing Unicode
- Python - unicode lib documentation
- Stackoverflow - lower() vs. casefold() in string matching and converting to lowercase
- Stackoverflow - How do I do a case-insensitive string comparison?
Blog posts
- My subconscious doesn't like LLMs 2025 Jul 16 | ~7 pages
- Computers understanding humans makes codebases irrelevant 2023 Apr 08 | ~5 pages
- Own your email's domain 2023 Feb 12 | ~4 pages
- Isolates + storage over http + orchestrators is the future that has arrived 2023 Jan 03 | ~4 pages
Articles
I learn through writing, so I write a lot. Most of these are ever evolving pieces.
DATA ENGINEERING
- The Spark Field Manual 2025 Oct 16 | ~23 pages
PYTHON
- Unicode string normalization schemes in Python 2024 May 06 | ~5 pages
RESOURCES
- Links collection 2025 Jun 15 | ~3 pages
- Papers, books, talks etc 2025 Jun 02 | ~4 pages
WORK
- Lecture - You and your research by Dr. Richard Hamming 2024 Oct 14 | ~49 pages